元学习器是利用一些现成的机器学习方法来进行因果推断的方法。也是相对来说最简单的进行因果推断的模型,在econml和causalml都有实现,调用也相对比较方便。
1.1. S_Learner
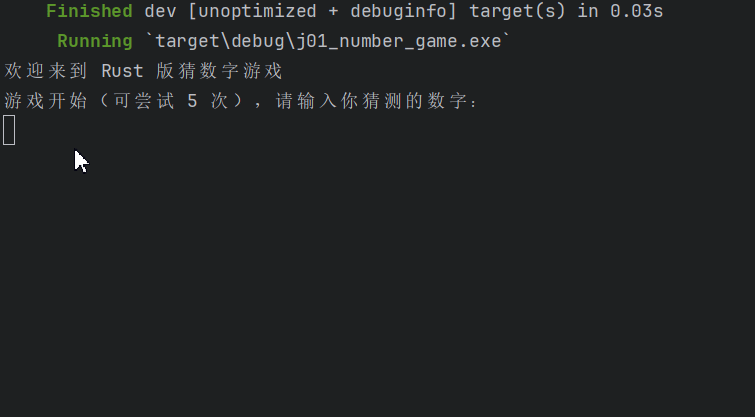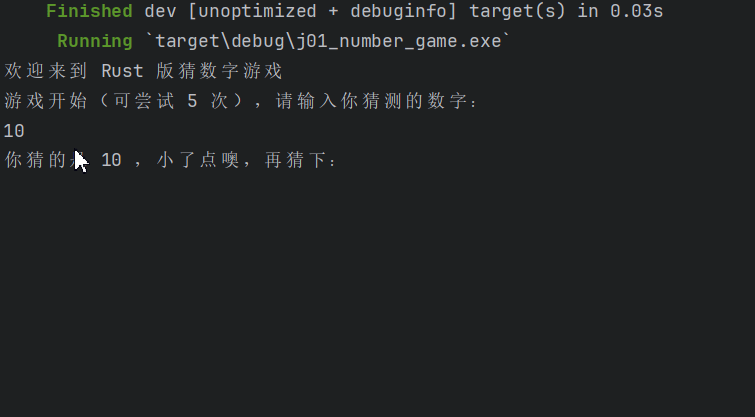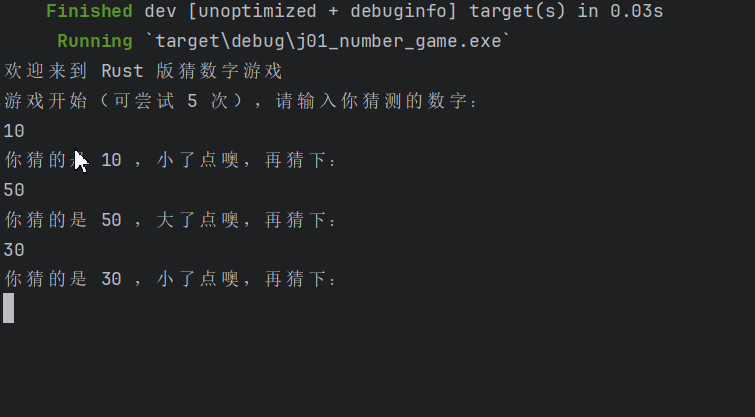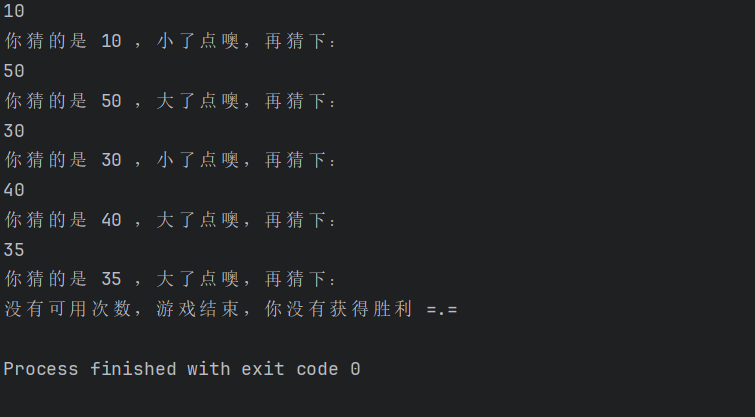
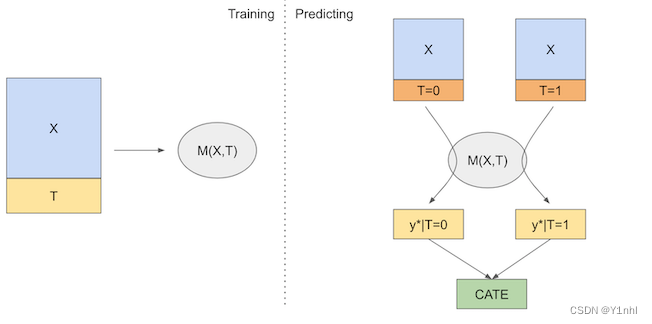
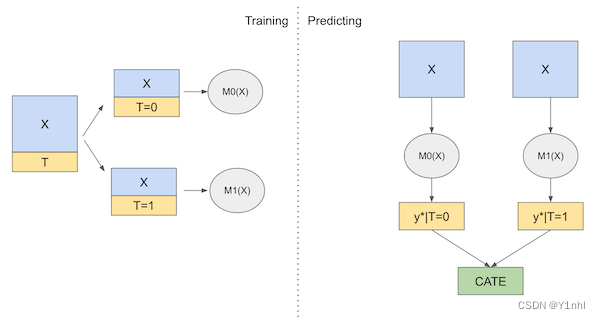
S 指的是 single,在S_Learner中,只需要训练一个机器学习模型,训练时把干预变量作为一个特征来预测结果,然后在不同的方案下做出预测,实验组和对照组的预测差异就是估计的CATE
优点:简单,易用
缺点:它倾向于把干预效果趋向于0,即真正的因果效应通常比估计的更大。
模型如下:
X是特征,T是干预变量,M可以是任意机器学习模型。
causalml调用S_learner
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from xgboost import XGBRegressor
from causalml.inference.meta import LRSRegressor
from causalml.inference.meta import XGBTRegressor, MLPTRegressor, XGBRRegressor
from causalml.inference.meta import BaseXRegressor, BaseRRegressor, BaseSRegressor, BaseTRegressor
from causalml.match import NearestNeighborMatch, MatchOptimizer, create_table_one
from causalml.propensity import ElasticNetPropensityModel
from causalml.dataset import *
from causalml.metrics import *
import warnings
warnings.filterwarnings('ignore')
# synthetic_data,是causalml.dataset内置的模拟数据函数,提供了4种mode,可生成4种数据
y, X, treatment, tau, b, e = synthetic_data(mode=1, n=1000, p=8, sigma=1.0)
# e:倾向性得分, treatment:干预变量(离散,二分)
print(y.shape, X.shape, treatment.shape, "\n", pd.Series(treatment).value_counts())
learner_s = LRSRegressor() # 线性回归
ate_s = learner_s.estimate_ate(X=X, treatment=treatment, y=y)
print(ate_s)
print('ATE estimate: {:.03f}'.format(ate_s[0][0]))
print('ATE lower bound: {:.03f}'.format(ate_s[1][0]))
print('ATE upper bound: {:.03f}'.format(ate_s[2][0]))
# output
(1000,) (1000, 8) (1000,)
1 550
0 450
dtype: int64
(array([0.76908845]), array([0.62108639]), array([0.91709051]))
ATE estimate: 0.769
ATE lower bound: 0.621
ATE upper bound: 0.917
其他参数:
p: 倾向性得分。
pretrain: (默认为False), 表示是否跳过训练。
ate_s = learner_s.estimate_ate(X=X, treatment=treatment, y=y)
print(ate_s)
print('ATE estimate: {:.03f}'.format(ate_s[0][0]))
print('ATE lower bound: {:.03f}'.format(ate_s[1][0]))
print('ATE upper bound: {:.03f}'.format(ate_s[2][0]))
# pretrain=True 表示跳过训练
ate_s = learner_s.estimate_ate(X=X, treatment=treatment, y=y, pretrain=True)
print(ate_s)
print('ATE estimate: {:.03f}'.format(ate_s[0][0]))
print('ATE lower bound: {:.03f}'.format(ate_s[1][0]))
print('ATE upper bound: {:.03f}'.format(ate_s[2][0]))
# output(两次估计结果一样)
(array([0.61557233]), array([0.46094647]), array([0.7701982]))
ATE estimate: 0.616
ATE lower bound: 0.461
ATE upper bound: 0.770
(array([0.61557233]), array([0.46094647]), array([0.7701982]))
ATE estimate: 0.616
ATE lower bound: 0.461
ATE upper bound: 0.770
1.2. T_Learner
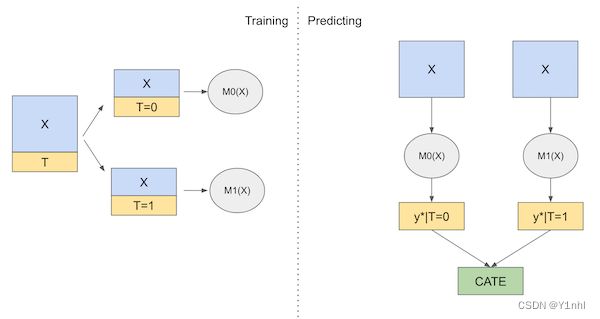
T指的是Two,在T_Learner中,通过干预变量对样本进行拆分,需要训练两个模型。
优点:避免了干预效果较弱的干预变脸被剔除模型的问题
缺点:存在过拟合问题,因为拟合的数据被分为了两个子集,数据点少了。
causalml调用T_learner
learner_t = XGBTRegressor()
ate_t = learner_t.estimate_ate(X=X, treatment=treatment, y=y)
print(ate_t)
learner_t = BaseTRegressor(learner=XGBRegressor())
ate_t = learner_t.estimate_ate(X=X, treatment=treatment, y=y)
print(ate_t)
# output
(array([0.68477325]), array([0.61274193]), array([0.75680456]))
(array([0.68477325]), array([0.61274193]), array([0.75680456]))
causalml提供了两种方式调用各种元学器,一个是直接实例化机器学习模型对应的元学习器,例如:XGBTRegressor();另一个是先实例化BaseTRegressor,然后再learner中指定需要的机器学习模型。从前面代码可以看到,估计的ATE是一样的。
其他参数:
bootstrap_ci=False : 是否返回效应区间
n_bootstraps=1000, bootstrap_size=1000 : 效应区间是通过 bootstrap方法得到的,这两个是相关参数
其中,BaseTRegressor还可以指定两次建模用不同的指定机器学习模型,如果直接指定learner = XX,那么两次建模都会用同一个模型
learner_t = BaseTRegressor(
control_learner = XGBRegressor(),
treatment_learner = LinearRegression(),
ate_alpha = 0.05, # 信效度
control_name = 0 # 控制组是哪一类
)
ate_t = learner_t.estimate_ate(X=X, treatment=treatment, y=y,
bootstrap_ci=False,
n_bootstraps=10,
bootstrap_size=10)
print(ate_t)
# output
(array([0.65123114]), array([0.53089023]), array([0.77157204]))
1.3. X_Learner
X_Learner同样包含两个阶段和一个倾向性得分模型
第一阶段与T_Learner相同,对干预样本和未干预样本分别拟合一个机器学习模型。
第二阶段使用上面拟合的两个模型来估计干预样本和未干预样本的干预效果,然后拟合两个模型来预测这些影响,最后通过倾向性得分模型来将两者结合起来。
- 当Treatment T和Outcome Y受共同的因素X影响时,就会发生混淆偏差。为去除偏差,需要控制住X,使得实验组和控制组的特征X分布一致,此时的Treatment独立于Y,满足无混淆假设,之后就可以正确地估计因果效应。去除混淆偏差的方法包括:
- 1.3.1. 倾向性得分匹配(Propensity Score Matching,PSM)
- 首先通过X预测T,得到一个条件概率P(T|X),也称之为倾向性得分(Propensity Score, PS),之后基于PS得分进行匹配,对于实验组的每一个样本,在对照组找到与之匹配(即二者相似)的一个样本,组成一个样本对,最后基于所有的样本对进行因果建模,以达到控制偏差的目的
- 1.3.1. 倾向性得分匹配(Propensity Score Matching,PSM)
learner_x = BaseXRegressor(learner=XGBRegressor())
ate_x = learner_x.estimate_ate(X=X, treatment=treatment, y=y, p=e)
print(ate_x)
# output
(array([0.41004427]), array([0.36615182]), array([0.45393672]))
1.4. 去偏机器学习(正交机器学习,双重机器学习(Double Machine Learning,DML)
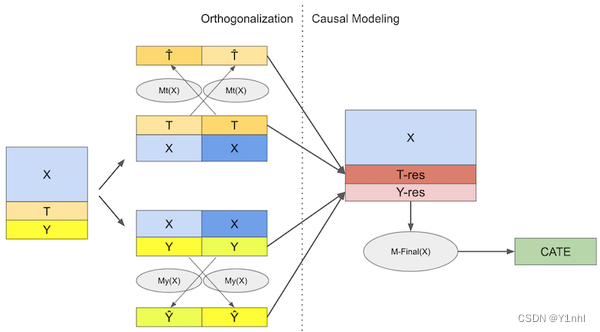
双重机器学习会训练三个模型,先采用两步正交化过程
- 训练一个模型Mt(x),用协变量X预测干预变量T,计算预测T和和真实T的残差 T ~ T\tilde{} T~。该模型称为去偏模型。
- 训练一个模型My(x),用协变量X预测结果变量Y,计算预测Y和真实Y的残差
Y
~
Y\tilde{}
Y~。该模型称为去噪模型。
有了这些残差,就能够在 T ~ T\tilde{} T~上回归 Y ~ Y\tilde{} Y~得到ATE的线性近似,进一步还可以采用机器学习模型估计CATE
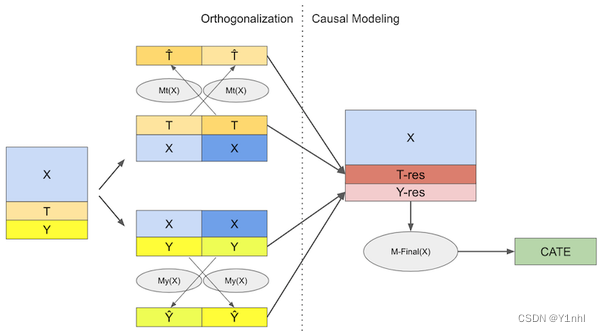
R_Learner就是双重机器学习方法的一种
learner_x = BaseXRegressor(XGBRegressor())
ate_x = learner_x.estimate_ate(X=X, treatment=treatment, y=y)
print(ate_x)
# output
(array([0.42084109]), array([0.37669545]), array([0.46498674]))
其他参数:
R_Learner还提供了sample_weights,用来给每个样本赋一个权重
learner_r = BaseRRegressor(learner=XGBRegressor())
sample_weight = np.random.randint(1, 3, len(y))
ate_r = learner_r.estimate_ate(X=X, treatment=treatment, y=y, p=e, sample_weight=sample_weight)
print(ate_r)
1.5. 元学习器计算Individual Treatment Effect (ITE/CATE)
元学习器计算CATE,都是统一采用的fit_predict()方法
# S Learner
learner_s = LRSRegressor()
cate_s = learner_s.fit_predict(X=X, treatment=treatment, y=y)
# T Learner
learner_t = BaseTRegressor(learner=XGBRegressor())
cate_t = learner_t.fit_predict(X=X, treatment=treatment, y=y)
# X Learner with propensity score input
learner_x = BaseXRegressor(learner=XGBRegressor())
cate_x = learner_x.fit_predict(X=X, treatment=treatment, y=y, p=e)
# X Learner without propensity score input
learner_x_no_p = BaseXRegressor(learner=XGBRegressor())
cate_x_no_p = learner_x_no_p.fit_predict(X=X, treatment=treatment, y=y)
# R Learner with propensity score input
learner_r = BaseRRegressor(learner=XGBRegressor())
cate_r = learner_r.fit_predict(X=X, treatment=treatment, y=y, p=e)
# R Learner without propensity score input
learner_r_no_p = BaseRRegressor(learner=XGBRegressor())
cate_r_no_p = learner_r_no_p.fit_predict(X=X, treatment=treatment, y=y)
遇到的问题:
1:根据定义,按理说R_learner已经能支持连续的干预变量,但BaseRRegressor依然不支持连续的干预变量
2:似乎causalml各种模型训练时,输入数据最好是numpy。我在jupyterlab上使用causalml的因果随机森林时,当输入数据是pandas格式,训练的时候,总是会内核死亡,并且在命令行提示窗口的log中也没报错提示,就是很自然的内核死亡,换成numpy格式就不会。。。